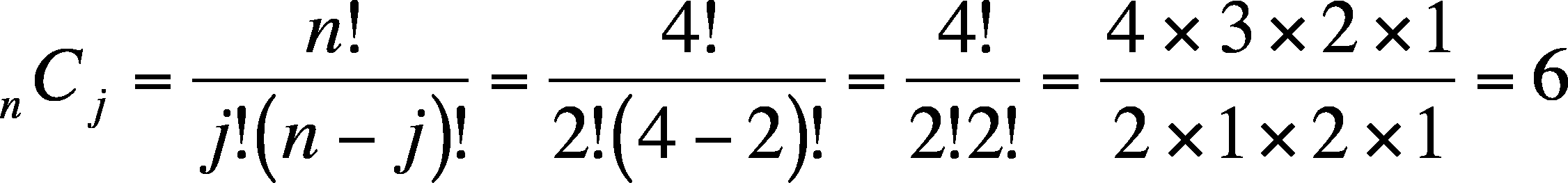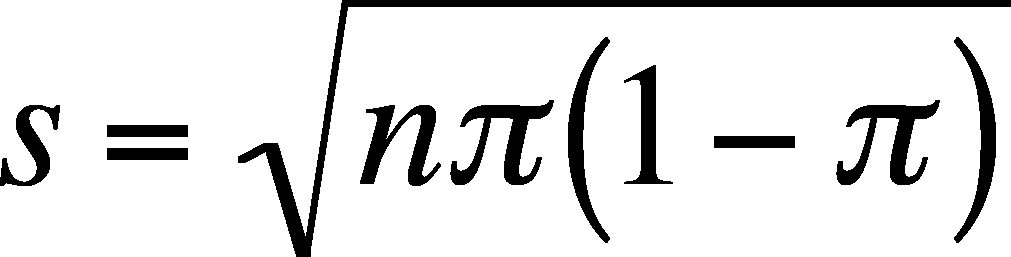|
BIOL 3110
Biostatistics Phil Ganter 320 Harned Hall 963-5782 |
| Sarracenia purpurea, a predatory plant |
|
|
BIOL 3110
Biostatistics Phil Ganter 320 Harned Hall 963-5782 |
| Sarracenia purpurea, a predatory plant |
|
Random Sampling & the Binomial Distribution
Back to:
Academic
Page |
Tennessee
State Home page |
Bio
311 Page |
Ganter
home page |
Unit Organization:
Problems:
Problems for homework
- 3.1, 3.3, 3.5, 3.7, 3.12, 3.17, 3.24, 3.27, 3.28, 3.33
Problems for homework - 4th Edition NOTE THAT THE MATERIAL IN THIS LECTURE ON RANDOM SAMPLING HAS BEEN MOVED TO THE FIRST CHAPTER OF THE 4th EDITION - YOU HAVE ALREADY READ THIS MATERIAL:
- 1.3.6, 3.2.1, 3.2.3, 3.3.1, 3.4.4, 3.5.7, 3.6.2, 3.6.3, 3.6.9
- 3.3 Consider a string of five randomly generated digits (whole numbers between 0 and 9). Random means each digit in the group of 5 has an equal probability of being a 0 or 1 or 2 or ... or 9. Let E stand for the event that all five digits in the string are different from the other members of the string. It can be shown that the probability of E is 30% (Pr{E} = 0.3). Use your calculator, a spreadsheet or the random number table in the book to generate 20 strings of 5 random digits. Keep a record of the data and, after each string is generated, calculate the cumulative proportion of strings that have no repeats.
Suggested Problems
- 3.9, 3.11, 3.13, 3.16, 3.26, 3.31, 3.45
- 3.2.5, 3.2.6, 3.3.3, 3.4.3, 3.6.1, 3.6.6, 3.S.8
Link to temporary page with the homework problems
Sampling is the process of selecting and measuring something of interest in a subset of a population. A sample is a representation of the entire population
Random means without any predictability
Random Sampling means selecting the sample so that all members of the population have an equal chance of being selected (you can not predict which members will be selected before the selection process takes place). This is also referred to as the Random Model
- Cluster Sampling randomly chooses groups of individuals rather than randomly sampling individuals. Ususally the groups are naturally occurring, not groups made by the experimenter
- Stratified Sampling breaks the overall population into subgroups that share some characteristic unique to members of the subgroup. Within each subgroup, individuals are sampled at random and the total sample combines the subgroup samples.
- this is useful when sampling a population where you know or suspect differences in responses from different subgroups and you want proportional input from each of the subgroups
- this sort of sampling may reduce sampling error only if there really is a difference among the groups
The statistics we will cover are based on the assumption that all samples are Random Samples!!
Random Number Tables and Random Number Generators available on computers
- Methods of Selecting
- Assign individuals numbers
- Picking a starting point
Parameter - true value of a measure (mean, s. d., var., range, etc.) based on the entire population
- usually designated with Greek letters (although all Greek letters do not mean parameters!)
Statistic - estimate of true value of a measure (mean, s. d., var., range, etc.) based on a sample (= a subset) drawn from the population
- usually designated by a regular letter with a bar over it.
- the most common letter used to designate a variable is x, so that the mean of x is often written as
Sampling Error
- assuming that the selection is random, then the difference between the sample statistics and the population parameters is the sampling error
- sampling error is unpredictable (for example, there is no way to tell if sample mean will be lower or higher than true mean)
Deviations from random sampling - error not due to sampling error
Bias - if some individuals are more likely to be chosen than others, this is bias
Homogeneity - if the range in the sample is not as wide as in the population, then the sample is too homogeneous. In this case, the sample mean may be unbiased, but the sample variance is too small.
Pr{E} = likelihood of an event occurring during a chance operation (E stands here for an event)
chance operation is an occurrence which is at least partially determined by chance
event -- selecting the correct lottery number
chance operation #1 -- buying one ticket
chance operation #2 -- buying one million tickets
How to determine probability
Theoretical models might do it if we have some expectation about the behavior of the system
for example, what is the chance of rolling a six with an honest die? - this is a theoretical estimation of a probability
Frequency Model - based on an empirical approach - let the data tell you what's happening
Pr{E} =
the number of times an event could occur depends on the number of times that the chance operation is repeated
Some Basic Rules:
- The probability of a particular outcome is between 0 and 1 (never occurs, sometimes occurs, always occurs)
- The probabilities of all possible outcomes must add up to 1
- The probability of a particular outcome not happening is 1 - probability of it happening
a variable the value of which depends on the outcome of a chance operation
Multiplying Probabilities (What is the probability that both event A and event B will occur?)
This is called the intersection of two probabilities (remember this term from set theory??).
Independent events are events where the chance of A occurring does not depend on whether or not B occurs (and vice versa)
Pr{A and B} = Pr{A} x Pr {B}
Pr{A and B} is usually written as Pr{AB}
Dependent events are where one event affects the probability of the other event occurring
Conditional Probability is the probability of an event, given that another event has happened and is written Pr{A|B} if the occurrance of A is related to whether or not B has occurred
Pr{A|B} = Pr{AB} / Pr{B}
Adding Probabilities (What is the probability that event A or event B will occur?)
This is called the union of two probabilities (also from set theory).
Pr{A or B} = Pr{A} + Pr {B} - Pr{AB}
add the probability of each event occurring and subtract the probability of both events occurring
If the two events are mutually exclusive (disjoint) - i. e. that both can not occur, then Pr{AB} = 0, and the formula reduces to
Pr{A or B} = Pr{A} + Pr {B}
A situation to which this rule can apply - what is the chance of rolling a die and getting either a 2 or a 5? In this case, only one of these situations can occur on a single roll of the die, so you can apply the rule and you get 1/6 + 1/6 = 2/6 = 1/3.
A situation to which this rule does not apply - what is the chance that rain will fall in Nashville sometime this week or the chance that rain will fall in the Amazon this week? In this case, both could occur, so they are not mutually exclusive. Violating mutual exclusivity invalidates the formula above.
If we assume that the chance of each is over 0.5 for each location (a reasonable assumption), then the sum would be over 1, i. e., the chance that either will occur is over 100%! This is impossible.
Combining Probabilities #2 - The Probability Tree
What is the probability that both event A and event B will occur?
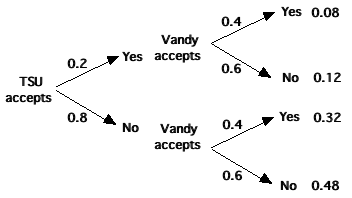
One may combine probabilities by keeping track of all possibilities with a probability tree. This is best demonstrated by example. Suppose you know that there is a 20% chance that you will get accepted by TSU as a transfer student (this is event A). Vanderbilt reports that it accepts 40% of all transfer applications. You apply to transfer to both schools. What is the probability that you will be accepted to both schools? What is the probability that you will be rejected by both schools? What is the probability that you will be accepted by TSU but rejected by Vanderbilt? A Probability tree will give the answer to all of these questions (assuming that all applicants have an equal chance of being accepted at each school's acceptance rate and neither school knows what the other is doing so that the events are independent). Look at the tree below. It is almost self-explanatory.
- As you can see, the probability of being accepted at both (follow the upper arrows) is 0.2 x 0.4 = 0.08
- The probability of being rejected by both (follow the lower arrows) is 0.8 x 0.6 = 0.48
- The probability of being accepted by TSU but rejected by Vanderbilt is 0.2 x 0.6 = 0.12
The four tips of the tree represent all possible outcomes (1. TSU yes/Vandy yes, 2. TSU yes/Vandy no, 3. TSU no/Vandy yes, 4. TSU no/Vandy no). This means that the sum of their probabilities must equal 1.0, which is so (0.08 + 0.12 + 0.32 + 0.48 = 1.00).
This is how we use the probability tree to find the intersection of two probabilities. The tree can also be used to find the union of probabilities. This is the combination of some of the outcomes from both events.
What is the probability that you will be accepted to at least one school? Before you read on, think about it and take a stab at it.
Well, look at the outcomes. Of the four outcomes, three have at least one yes (1. TSU yes/Vandy yes, 2. TSU yes/Vandy no, 3. TSU no/Vandy yes)
The sum of the probabilities of these outcomes is 0.08 + 0.12 + 0.32 = 0.52. Is this greater or less than you would have expected before reading this analysis?
Notice that I combined three probabilities for the last answer. That was because of the wording of the question. Had I asked "What is the probability of being accepted to one school?" and left out the at least, the answer would have been different.
Only two outcomes result in acceptance by one school (2. TSU yes/Vandy no, 3. TSU no/Vandy yes) and the sum of their probabilities is 0.12 + 0.32 = 0.44.
Would the answers differ if the events had been put into the tree in reverse order (Vandy acceptance first, TSU second)? Make a tree and find out.
Probability Distributions (Density Curves in the book!)
set of probabilities corresponding to all possible outcomes of a chance operation
Look to the book for how they are graphically depicted - they are like frequency diagrams (in fact, they are a type or frequency diagram)
x-axis represents all possible outcomes
y-axis represents the probability of each of those outcomes
if you sum up all of the probabilities for all of the outcomes, they must sum to 1
if they don't then either a probability is wrong or not all outcomes have a probability assigned to them
Independent-Trials Model - you can apply the binomial if the assumptions of the ITM apply to a situation. The assumptions are very general and so this can be widely applied
- n trials are conducted
- event E either occurs (a success) or does not (a failure) during each trial (so that the sums of the two possibilities is 1)
- the probability of E occurring in each trial is
, and does not change from trial to trial
The binomial is the way to answer the following question: What is the probability of j successes out of n trials when the probability of a success is
Example --
We will use 4 trials (n = 4)
A trial consists of choosing a red ball from a group of three balls (two are black or simply not red) so that
What is the probability of getting two red balls out of the four trials (j = 2)? There are six ways of drawing 2 reds out of four draws and the probability of getting each is calculated below. Note that it is the order in which the red balls are drawn out that changes between each of the six possibilities.
Pr{two red choices out of four} = sum of six possible outcomes above = 24/81
this total is the overall probability of drawing 2 reds out of four (no matter in what order) gotten by adding the probability of all six possible ways of drawing 2 red balls out of 4 draws.
This probability can be calculated from the Binomial Distribution
Pr{j successes out of n trials} = nCj
nCj = the Combinatorial = the number of combinations with the right number of successes
For the situation in which we are interested in 2 successes out of 4 trials (each trial is a chance for success), then
(see Appendix 3.1 in the text)
Mean and s.d. of the Binomial
The mean of the binomial (=expected number of successes out of n trials) can be arrived at through simple logic. If the probability of success is
numerical example - probability of catching a fish on any day is 0.20. This is
The standard deviation's formula is more complex and so it its derivation. I will refer you to Appendix 3.3 in the book for the derivation, but the formula is:
Application of the Binomial
Dichotomous outcomes
A and not A (e. g. the animal survives or does not)
Notice that the chance of the event occurring must be the same for all events
if you are sampling from a population, then
A) you must place the sampled individuals back into the population (sampling with replacement)
B) the sample must be such a small fraction of the total population that its removal does not significantly change the probability of any particular outcome (unofficially called the Fudge Factor)
Fitting the Binomial to Data
Suppose that you have a situation in which you can count the outcomes until you get a large sample. You can fit the data to the binomial distribution of the situation conforms to the independent trials model.
Here is a situation. Suppose that you are investigating the density of a rare species of plankton in a lake. Often a single sample has none of your target specie in it. You row across the lake and take four samples from it as you row each day of sampling. You sample for 100 days.
You might want to ask of the data whether or not the chance of getting the target species in a sample is random. The binomial can help answer the question. If it is, then all samples are equally useful in determining the density of the plankton. If the chance is not random, then some of your samples might be less (or more) likely to have contained plankton (perhaps because the plankton is closer to the surface on cloudy days and you are more likely to find it on those days even though it is in the lake on all days) and so, some samples are more useful than others for determining density.
Remember the assumptions of the Independent Trials model. The chance of success must be equal for each trial. This means all samples must have the same chance of having the target species in them.
How to test this. First you need the data. The table below has it plus all of the calculations we need
Successes Actual Data n j C Binomial 0 21 0.21 0 4 0 1 0.15 14.8 +6.2 1 38 0.38 38 4 1 4 0.36 36.2 +1.8 2 19 0.19 38 4 2 6 0.33 33.3 -14.3 3 12 0.12 36 4 3 4 0.14 13.6 -1.6 4 10 0.1 40 4 4 1 0.02 2.1 +7.9 Totals 100 1.0 152 1.0 100 0
From left to right -
Column 1 - This lists the number of sample jars in one day that had some of the target species. It goes from 0 to 4 because there were only 4 samples taken in any one day
Column 2 - This is the number of days that produced the number of successes in column 1. Another way to say this is that this is the frequency of each outcome in column 1. For instance, there were 10 days on which all four jars had the species of plankton. Notice that the actual data column must sum to 100 (see above) because we sampled on 100 days
Column 3 - This is the proportional frequency calculated by dividing the actual data by the total number of sample days.
Column 4 - This is the product of columns 1 and 2. It is the total number of jars with the target species for that level of success. The total is 152, which means there were 152 sample jars with the species out of the total number of jars collected. The total for all collection jars is 400 (4 jars each day, 100 days). This is done to calculate
Columns 5 & 6 - These are listed to calculate C, the number of ways to get j successes in n trials. J goes from 0 to 4 and n is always 4.
Column 7 - This is C, done from the formula C = n!/j!*(n-j)!
Column 8 - This is the binomial probability of getting j successes out of n trials {=
Column 9 -This is number of days on which you should have gotten j successes (j jars with the target species out of 4). It is calculated by multiplying the binomial probability times 100 days (the total number of days).
Column 10 - Here we compare the real data with our calculated binomial expectations. This column is column 2 (the data) minus column 10 (the expected number of days according to the binomial). Notice that these differences sum to 0 because you have to balance any excesses with deficiencies if the sum is always 100 days.
Notice that there is a pattern to the error. The + rows are at the beginning and the end. This says there were too many days on which the species of interest was found in no jars and too many days when it was found in all four. In other words, instead of a constant probability of finding the species in a sampling jar, some days were very good and some were very bad.
Last updated January 22, 2013